Often times I had to change something in our infra code workflow and needed a quick way to test a specific bicep file.
In the terminal, make sure you are in the folder which has the bicep file. And then use the deployment command as shown below and it will deploy it to the resource group you have mentioned. And pass in the parameters thats needed for the bicep.
az deployment group create –resource-group my-resource-group –template-file .\storage.bicep –parameters environmentName=something environmentType=dev environmentLocation=eastus2 resourceGroupName=my-resource-group
Its trivial. But often times I forget this deployment command and the idea of changing a bicep file intimidated me. But with this command, we can verify the bicep file itself does everything we expect and we can add this to the overall workflow later
I work predominantly in C# and ASP.Net and I am more comfortable working with Microsoft SQL server in all projects. My personal laptop being a Mac its always a struggle to get it working especially with M1 and ARM. Docker always comes to the rescue in these situations and I am just listing down the steps here, so that I can come back to this blog later.
Have docker installed in your system if you don’t already have it. Once you have docker, type in the following command to get the latest sql server. At the time of this post, its 2022 for me.
Next run the following command, which actually installs the image with a default user SA and password configured. Make sure to use the password of your choice, but it needs to be a strong password which fulfills the sql requirements.
This should list your containers and take a note of the container id
docker ps -a
You can also find the same in the GUI. Take note of the container id since we will be using it in next command. I always like to have the AdventureWorks sample database from Micosoft to be in the db. Allows me to quickly check some sql queries. For that, first download the Adventure works from the link below.
Assuming its in the Downloads folder by default, use the below command to copy this into the folder in the container where sql server is installed. Change the folder path and container id to suit your needs.
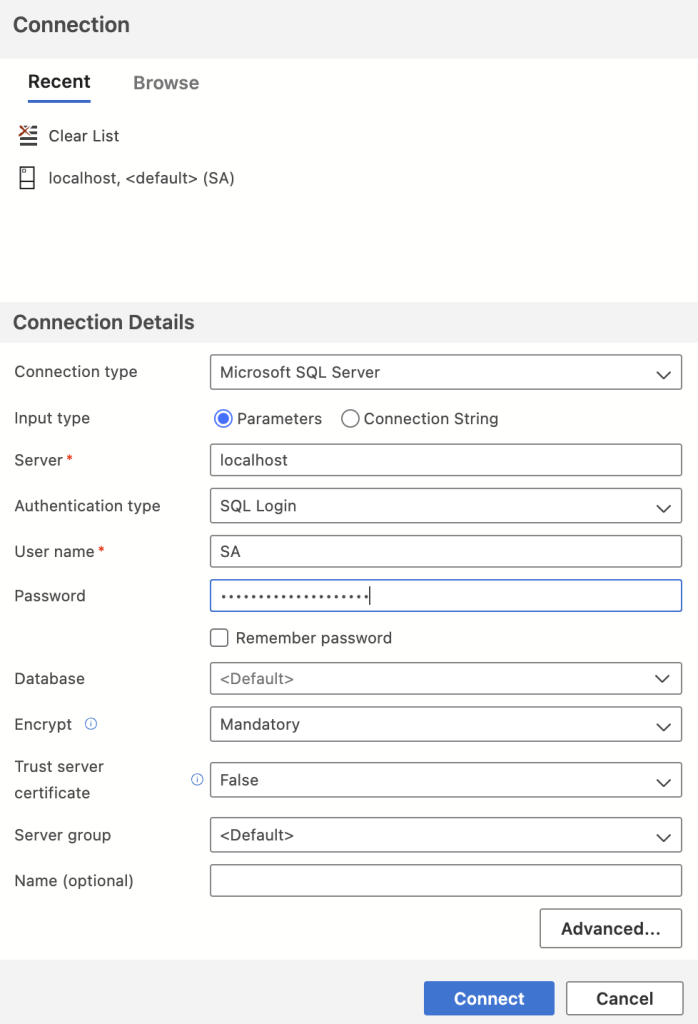
Now we need a client to connect to the server. I am using Azure Data Studio these days. Download and install Azure Data Studio and then click on New Connection.
With the above commands we have a default user SA. So enter Server as ‘localhost’, SQL Login with SA and password should connect to the server in docker container.
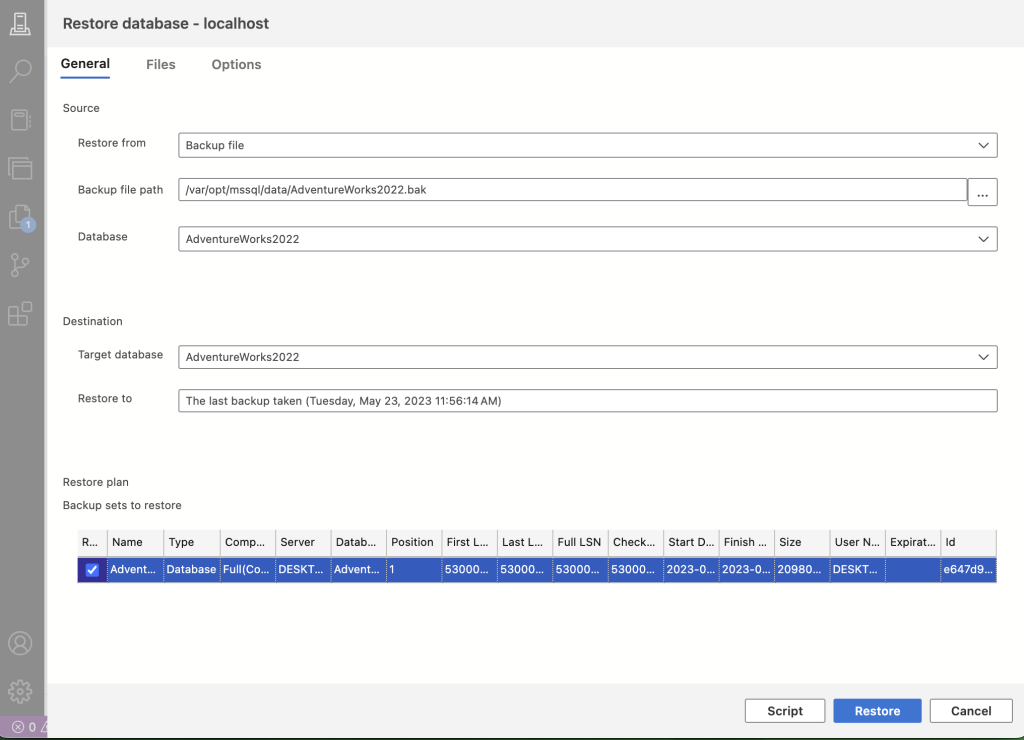
Remember we copied the AdventureWork2022 into the container folder. Next we need to restore database from that back up file. On bottom left of Data studio, we have settings, and then Command Palette. Type Restore in there and you should get the UI for selecting the type of restoration we need. A sample reference is given below:
And thats it. We have a sql server running in docker which has AdventureWorks2022 restored. Enjoy querying !
It is quite common to have usecases where we need to parallel execution to have over items in a list and wait for the whole process to be complete. C# allows tasks to achieve this result. But there are many ways to do the same and here I am just exploring some of the ways, I have done it in my projects.
In the below example, we are using a ConcurrentBag list to store the content returned by the async function ProcessContent. This works and fetched consistent results. But I am not sure on the thread exhaustion since we are using Task.Run inside the lambda. Task.Run is usually used to make sure a new thread is used to execute the function call based on threads availability
var fullList = new ConcurrentBag<SomethingViewModel>();
var tasks = new List<Task>();
contents.ForEach(content => tasks.Add(Task.Run(async () =>
{
SomethingViewModel contentComplete = await ProcessSomething(content, token);
if (contentComplete != null)
{
fullList .Add(contentComplete );
}
})));
This method uses projection instead of forEach used above. Tasks are then assigned to an array and then projected again to a list based on null check
var tasks1 = contents.Select(x => ProcessContent(x, token))
.ToList();
SomethingViewModel[] result = await Task.WhenAll(tasks1);
IEnumerable<SomethingViewModel> fullResult = result.Where(x => x is not null);
Third method involves using the Paralled.ForEachAsync method. This works, but had the least response times when testing for performance.
The above 3 methods worked. First 2 methods dont give the option to control the number of parallel threads and hence might cause memory issues. At the same time, when we have I/O operations like calling external apis, saving to database, the default safe way is to use the Task.WhenAll approach. I ended up using Option 2, but might revisit this later based on memory usage analysis from production.
I was recently setting up a react project and was getting error saying port in use. And unlike in mac , needed few more commands to make it work in windows.
So when you want to kill a port, first it helps to find out which app is using it. Find the PID number and then use that to kill the process
netstat -ano | find "LISTENING" | find "3001"
taskkill /pid <pid number from above> -f
If you want to kill all processes, you can use this command
taskkill /im node.exe
Remember you might have to use -f to force it. Also make sure to run the terminal with admin privileges
In mac, you can use killall
killall node
To kill specific port number in use in mac, use the lsof command
lsof -i:3001
Note down the PID number just like in windows. And then use the kill command like below
Recently I had to work in a worker process project and after deployment, something wasn’t right. After spending hours, realized that the application was not loading the right configuration files. So this article is a self note on how to configure app to read from the appsettings in a dot net core environment.
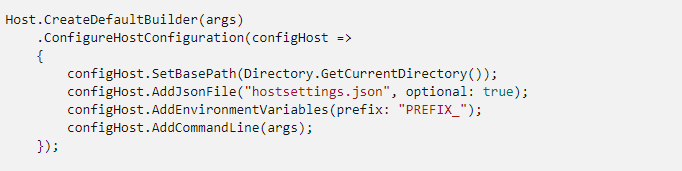
Following Microsoft article is a good starting point. This would provide a general idea about hosting in dot net core
Now the above snapshot works for web apps, but when it comes to worker process, that GetCurrentDirectory() will default to System32 folder and not the application folder. Hence the importance of using UseWindowsService() as explained in the next article below.
GetCurrentDirectory() gets you System32 folder which is not what we want.
Use ContentRootPath to set the directory path explicitly, but by default its set to the AppContext.BaseDirectory which is our app location
There is no need to explicitly set the SetBasePath() since the app directory would be set by default, and thus any appSettings file will be loaded
Now comes the section where we should set the Environment variables in the server. When we run from Visual Studio locally it finds the Environment name set in the project properties > Debug. To set the same in the server , type the below code in command prompt.
Worker process or console apps are prefixed with DOTNET and web apps are prefixed with ASPNETCORE
setx DOTNET_ENVIRONMENT “Development” /M
The above command would create a Environment variable in the server and in our App configuration in the Startup when we add the command config.AddEnvironmentVariables() , it would add default variables which are prefixed with DOTNET for worker process.
We can have the app add other environment variables with specific prefixes by setting it as config.AddEnvironmentVariables(prefix: “PREFIX_”);
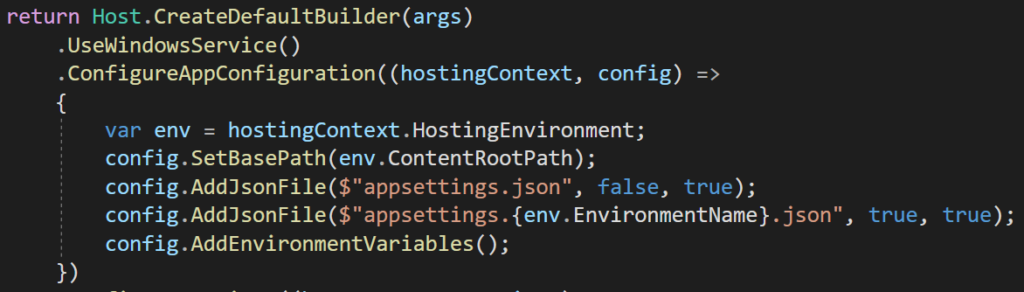
Final configuration for a worker process
This is the final version I had. We don’t need to specify SetBasePath, but I am doing it. Also remember that AddEnvironmentVariables() is last , so it would overwrite final env variable even from the json config. So make sure you have right system environment variable setup in the remote server.
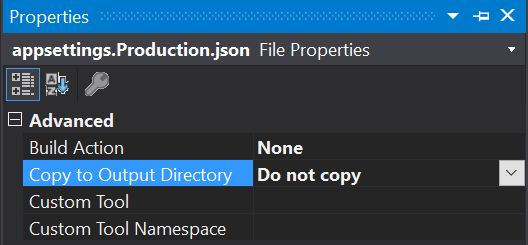
And make sure to disable Copy To Output field for other environment AppSettings file, since we don’t want Dev Server having config files pointing to Production. Even though it won’t be picked, remember that default Hosting Environment is Production, so if the variable wasn’t set by any chance, the app would be using Production config files, if its present in the dev server. It would be a manual process to change it to Copy before publishing to Production.
Even with this configuration, my log files are still generated in the System32 folder by deafult. This happens only when you run the app as a windows service. Solution was to set the logfile path the in the Serilog configuration using the command below. AppContext.BaseDirectory.ToString() gives you the app directory path.
Application Insights is a monitoring service Microsoft provides which is now grouped under Azure Monitor. We use it monitor our applications and extremely useful in production environments. I spent most of the time in Transaction search when I have to look into deployed applications and it allows to see all the requests made apart from the trace and dependencies. Its extensible, so apart from providing most of the features we need out of the box, we can customize it and modify the default way of things.
In this blog, I just want to share a recent use case, where we had to add custom HTTP headers into application insights so that we can trace the id across multiple services. The standard way of doing it is explained in one of the Microsoft blogs that I have linked below. Its done in dot net framework style, so if you want it in the dot net core method, just have IHttpContextAccessor in the constructor to dependency inject and use HttpContext from that in place of sections where the blog uses HttpContext.Current. Also the way its registered in startup is obsolete, so just have the classes added to the container like :
But I was using the Microsoft provided NuGet package for header propagation. When I have a header “YourId” in the incoming request, I should use it. If it’s absent, my application would generate a new GUID and I need to transfer this value as “YourId” in the header for the next request made by the service.
Initially I created the TelemetryInitializer class and had the GUID logic in it. It worked when the incoming request already had the header. But when my service had to create a new GUID for the header, the right id wasn’t being populated into the application insights. This is because the GUID was generated in Telemetry class which doesn’t work well with the header propagation rules of the NuGet package.
As it turned out, all I wanted was the ability to add the id to the Telemetry as soon as it was created. I didn’t know how to get hold of the telemetry object in the Startup class. All I needed was the below line of code.
var requestTelemetry = context.HttpContext.Features.Get<RequestTelemetry>();
The above line gives you access to RequestTelemetry object which then gives you access to its properties. You can see the complete code below.
services.AddHeaderPropagation(options =>
{
var correlationId = "YourId";
options.Headers.Add(correlationId, context => {
var requestTelemetry = context.HttpContext.Features.Get<RequestTelemetry>();
if (context.HttpContext.Request.Headers.TryGetValue(correlationId, out var value))
{
requestTelemetry.Properties[correlationId] = value.ToString();
return value.ToString();
}
else
{
var guidId = Guid.NewGuid().ToString();
requestTelemetry.Properties[correlationId] = guidId;
return new StringValues(guidId);
}
});
});
So this allows you to delegate the job of header propagation to the Microsoft NuGet package, but also add the ids to application insights based on the condition. If you want to checkout basic header propagation, check my earlier post linked below.
I guess not many people face these kinds of issues or there might be better ways to do this. I posted the question in stackoverflow and I had to answer it myself. 🙂
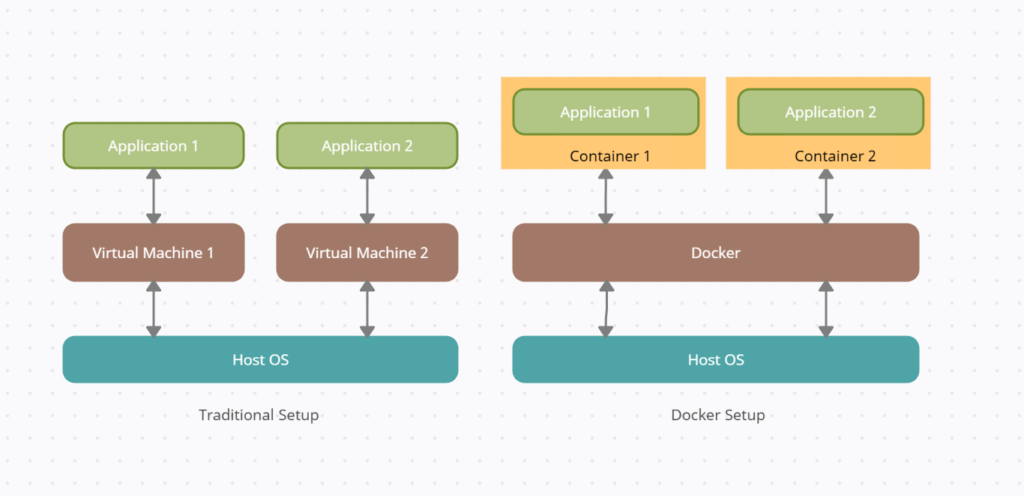
By now everyone is familiar with the idea of containers and docker and how those words are used interchangeably like search and google. This article is more like a self reference to some of the basic ideas and commands around docker for reference.
Docker or containers in general came to solve the typical software problem, “It works in my system and not in Prod”. If you look at a typical dot net application in our laptop, it has many dependencies around which framework sdk or runtime is installed and your project might have some other dependencies, need to install Enterprise Library 5.0 or something like Spreadsheet gear , in the dot net framework days. The point is you have these dependencies which need to be installed in your environment and chances are, when you deploy to the dev server, you might forget to install one of these dependencies and sometimes (most of the time) the errors you get will be misleading. After hours of debugging you realize, forgot to install that special one.
Docker helps to solve that problem. All the dependencies are listed in a docker file and once configured, the app runs in a sandbox environment and it makes no difference whether its your laptop or the production server. Except for the crashes I get for the limited memory on my laptop. 😉 But the importance of this for CI/CD deployments like in Azure DevOps cant be stressed enough. It gives you the confidence that, if its working in my system, it will work on the server.
Docker helps you instantiate lightweight containers from docker images, which can run in any system where you have Docker Desktop installed. With a typical dot net application, it starts this multistage process, where it builds layer after layer with all the dependencies mentioned in the docker file. Once this file is composed and you create a docker image, you can replicate this process across all your environments with the same docker file. This is what brings the consistency needed across environments.
If you been a Microsoft developer from the old days, one of the first things you would appreciate is the evolution of Microsoft docs. Everything is explained so neatly, these days I rarely have to look elsewhere. Looks like they have an equally paid team to develop the docs. 🙂
When you select Docker while creating a new project, that Docker file will have the necessary info to create a docker image, where it downloads the necessary files from the Microsoft container registry. If you work in a enterprise environment, you will notice that, you would have to change these settings, since they would have a container registry of their own with a pre-approved list of images.
Standard docker file from microsoft
# https://hub.docker.com/_/microsoft-
dotnet FROM mcr.microsoft.com/dotnet/sdk:5.0
AS build WORKDIR /source
# copy csproj and restore as distinct layers
COPY *.sln .
COPY aspnetapp/*.csproj ./aspnetapp/
RUN dotnet restore
# copy everything else and build app
COPY aspnetapp/. ./aspnetapp/ WORKDIR /source/aspnetapp
RUN dotnet publish -c release -o /app --no-restore
# final stage/image
FROM mcr.microsoft.com/dotnet/aspnet:5.0
WORKDIR /app
COPY --from=build /app ./
ENTRYPOINT ["dotnet", "aspnetapp.dll"]
One thing they dont talk in that page is to use dockerignore. We dont want bin and obj folders in our container image. So just create a .dockerignore file in the same level as docker file and add these 2 lines or more if have other folders to ignore
bin\
obj\
Lets now come to some common commands that we use in docker and assume my docker image is called cheers.
docker build -t bobbythetechie/cheers
In the terminal, make sure you are browsed to the location of the docker file. The above like will start to build the image and will tag with the name given. Its a normal practice to use your docker hub id and the follow up with the name you want to give for the image. This helps it make unique and if you ever want to publish it to the docker hub, it helps.
To version, just use the build command with colon as shown above. If you dont provide it, docker will version it as “latest”.
docker run -p 8080:80 bobbythetechie/cheers
Finally run the docker image. Now the reason I put in that -p tag is, thats one of the things I always forget. Understand that when we build docker images and especially when we use Docker compose, we can have multiple projects , like lets say we want to run 3 web apis at the same time along with a messaging service like Kafka and all the dependencies that comes with it. To avoid all these services clashing with same port numbers, we can specifically tell which port number each service should use right in the docker image.
# final stage/image
FROM mcr.microsoft.com/dotnet/aspnet:5.0
WORKDIR /app
EXPOSE 80
COPY --from=build /app ./
ENTRYPOINT ["dotnet", "aspnetapp.dll"]# final stage/image
You can see that I modified the standard Microsoft docker file to say, when you build that image, make sure its using port 80. Now this is the port inside the docker container. When we actually run this image, we want to say expose it to another port number, which we can use to access the app. So in the below example, port 80 internally maps to 8080 externally. So we can access this app only through 8080.
docker run -p 8080:80 bobbythetechie/cheers
We might want to see the list of containers that are running in the system and thats when we use command ps.
docker ps
Something similar to the above image. Its useful when we have lots of containers and Visual Studio can be misleading at times.
Next is pushing this image to dockerhub, so that you can use it anywhere. (Needs internet 🙂 )
docker push bobbythetechie/cheers
It might ask for your docker hub credentials and after that, the image is pushed to docker hub. In enterprise environments, its going to be a company repository, but the idea remains the same.
Now that its in the docker hub, all you need to do is go to the new environment and run the same command, but this time the image will be downloaded from the hub into the new system and it will run the same. Since the docker hub id is unique, docker knows the image it needs to download.
docker run -p 8080:80 bobbythetechie/cheers
I guess that would be it. Some of the basics around docker for a dot net developer. There a few more changes and configurations when working in an enterprise environment, but the basic idea remains the same. And even though we play around in the beginning to get it right when there are multiple systems involved, once we have it configured, you can be rest assured it will work every time , everywhere.
.Net core has made it super easy for header propogation, which is to transfer the header information from one http request to subsequent requests along the line, across multiple services. One common use case is to transfer the token information to subsequent services which are called down the line.
The above link points to the Microsoft documentation and that’s pretty much what’s needed for implement the feature. The only issue I had was, when I tried to implement it, the header value was getting overwritten with the default value in the response.
I wanted the service to just transfer the header info if it was present, and if it was absent, create the header with a new GUID and transfer to services down the line. I tried to write many conditions to achieve the same, but at the end it was just adding both lines together.
When we add both those lines above , the first line helps to transfer the X-TraceId to the next service. If its not present, then the second line kicks in and adds the header along with a new GUID to the next service. This is exactly what I wanted. Problem solved !
After selecting region, and WordPress, I opted for the cheapest plan possible.
Lightsail console has a SSH quick connect icon, which connects you to the WordPress instance. Once you get the password, you can go to the wordpress site and login with those credentials to be admin.
Make sure you create a static ip in the light sail console and attach it to the instance. This makes sure that, even when your instances restart, there is a constant ip which you don’t have to reconfigure to the domain.
You can create a Lightsail DNS zone, but I already had Route 53 configured in my previous attempt to run the WordPress site from the EC2 instance. So I just reconfigured the Lightsail to use the Route 53 settings. Now if that turns out to be expensive, I would have to do in the Lightsail.
Now AWS uses bitnami to create the wordpress instance. So there are a couple of things you have to do, once the site is up.
First thing is to have SSL certifcates installed. There are 2 ways to do it and Amazon has some really great documentation in that regard. Follow the step that works for you. Bncert tool takes the hassle away of renewing the certificate every 90 days, but Certbot allows to have a wildcard certificate, which means you dont have to create a new certificate if you have multiple subdomains to your site.
Second thing is to remove the Bitnami banner from your site. For that follow the instructions in the following link, except you might have to change the bnconfig to bnconfig.disabled, which was my case.
Dot net core was a revolutionary step up in many ways, from the old dot net framework. But one of the fav things I love about core is its cross platform support. And if we learn some of the CLI commands we can use it across Windows, MacOS or Linux.
dotnet new creates a .net project followed by template of choice
Some of the common templates are :
Console Application – console
Worker Service – worker
Blazor Server App – blazorserver
Blazor WebAssembly App – blazorwasm
Asp.Net Empty – web
Asp.Net Core Web App (MVC) – mvc
Asp.Net Core Web App – webapp
So if we wanna create a brand new razor page application:
dotnet new sln -n MyApp
dot net new webapp -o MyApp
dotnet sln add MyApp
sln creates the solution, webapp creates a asp.net core application and the third line adds the app to the solution
Next set of commands would be :
dotnet restore //Not relevant nowadays since Visual Studio would always do it by default, but important for CI/CD pipelines. It brings all the dependencies related to the project to the local folder. The dependencies are listed in the csporj file which inturn is a XML file
dotnet build //Builds the application and if there are no errors, will produce the output
dotnet run //Takes the above build output to run the application
Another common feature is to add Nuget packages. For that use the below command, replacing ### with the package name